
HTTP status codes form the backbone of server-client communication on the web, signaling the result of a request. Among them, the 200 status code is perhaps the most recognized.
It signifies that a request has been successfully processed by the server. However, business owners often encounter confusion when a “200 OK” code appears alongside faulty behavior on their site or app.
This misunderstanding can obscure real issues. In this article, we’ll clarify what the 200 code truly indicates, explore why it can be misleading, and offer insights into how to approach such scenarios with technical precision.
Table of Contents
What Is HTTP Status Code 200?
The HTTP status code 200, known as “OK,” indicates that a server has successfully received, understood, and processed a client’s request. It is the standard response for successful HTTP transactions, such as loading a webpage, submitting a form, or fetching data from an API.
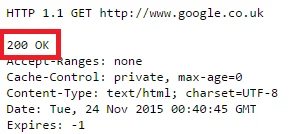
In most cases, this code is accompanied by the expected payload, such as HTML content, JSON data, or a file download.
The 200 response is a protocol-level confirmation that everything from the HTTP request’s standpoint functioned without errors. It does not, however, assess the quality, accuracy, or validity of the returned data.
A 200 code simply means the request didn’t violate protocol rules, not that the result is useful or even correct. It makes it a success signal in a technical sense, not necessarily a functional one.
Understanding this nuance is crucial for diagnosing inconsistencies in data-driven applications and user-facing systems.
Why a 200 Code Might Be Misleading
Despite indicating technical success, the 200 status code can mask underlying problems when misused or interpreted in isolation. One major issue arises when a server returns a 200 status even though the content signals failure.
For example, an API might return { “error”: “Invalid user ID” } with a 200 status, misleading both automated systems and human analysts.
Another common scenario occurs in websites where missing or corrupted content is delivered with a 200 code. This miscommunication prevents search engines or monitoring tools from detecting faults. In such cases, a 404 or 500 code would be more appropriate and informative.
Examples of misleading 200 responses include:
- A failed form submission that displays a generic “Thank you” page.
- An empty data response from an API still marked as 200 OK.
- An internal application error rendered as a success page for the user.

Without proper backend logic, 200 can act as a false signal of operational health.
How Developers Should Handle 200 Responses Carefully
The 200 status code must be paired with accurate application logic to reflect the true state of a response. Misuse can lead to false-positive monitoring reports, poor user experience, and missed debugging opportunities.
- Validate Output Alongside Status: Ensure that the actual response body aligns with what a successful result should contain. For example, a REST API returning an error message should not respond with 200, but with 400 or 422.
- Use Condition-Specific Status Codes: For failed operations like unauthorized access or invalid input, use 401, 403, or 422 as appropriate. It keeps your system semantically correct and easier to maintain.
- Log Both Status and Payload: Maintain comprehensive logs capturing both HTTP codes and returned data. This helps identify patterns where 200 responses don’t match expected functional behavior.
- Automate API Schema Validation: Use middleware or tools like Joi or Yup to enforce consistent response structures and avoid returning incomplete or erroneous 200 responses.
- Avoid 200 on Server Failures: When something breaks (database issues, internal exceptions), return 500-series errors. This prevents silent failures and ensures alerts are triggered.
Best Practices to Prevent Misleading 200 Responses
Developers and engineering teams can safeguard application transparency by following a few technical practices, aligning status codes with response integrity.
- Implement centralized error handling across your codebase to ensure appropriate status codes are returned.
- Use integration tests to verify not just business logic, but also the correctness of response codes.
- Set up automated monitoring to flag high volumes of 200 codes paired with unexpected payloads.
- Leverage API specification tools like Swagger/OpenAPI to enforce expected outputs and responses.
- Educate teams about semantic HTTP practices to avoid defaulting to 200 out of habit.
Conclusion
While HTTP status code 200 is foundational to web interactions, its simplicity can be deceptive. For business-critical applications, treating it as a guarantee of success can lead to blind spots in diagnostics and data integrity.
Aligning response status with actual outcomes ensures more reliable automation, monitoring, and user trust. It’s not just about what the server says; it’s about whether what it says makes sense.
